
索引统计的更新机制
选择索引是优化器的工作,优化器选择索引的目的是为了寻找一个最优的执行方案,并用最小的代价去执行语句。
在数据库里,扫描行数、是否使用临时表和是否排序等是印象执行代价的因素之一。其中扫描行数越小意味着访问磁盘数据的次数越少,消耗的 CPU 资源就会越少;而如果用到的索引正好是排序字段,由于索引是排好序的,因而能够减少因排序产生的消耗。
而扫描行数是被基数影响,
MySQL 在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。 这个统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。
使用 show index from your_table_name; 能看到这个表上索引的区分度,对应的字段是 Cardinality:

使用 explain “查询语句”; 能看到执行语句的预估扫描行数:
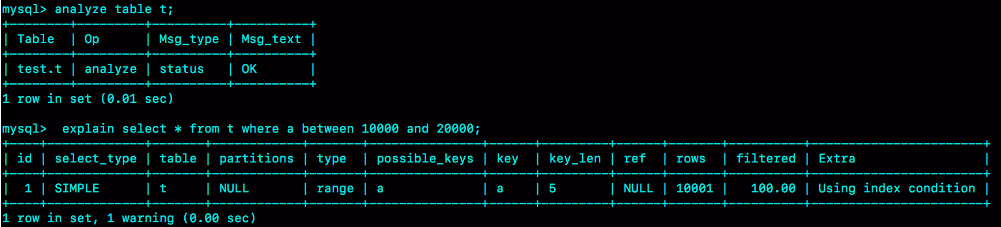
其中 rows 对应的就是扫描行数,如果发现预估的扫描行数与实际选中对应的索引会扫描的行数相差过大,这时候可以使用 analyze table your_table_name; 用来重新统计索引信息。
索引选择异常和处理
对于其他优化器误判的情况,可以在应用端用 force index 来强行指定索引,也可以通过修改语句来引导优化器选择我们想让它选择的索引,还可以通过增加或者删除索引来绕过这个问题。